月成本3500美元 如何在AWS上实现BBVA信用卡低延时分析
这篇文章由Datasalt的创始人Ivan de Prado和Pere Ferrera提供,Datasalt是一家专注于大数据的公司,推出了Pangool和Spoilt SQL Big Data等开源项目。在这篇文章中,通过BBVA信用卡支付的例子详解了云计算中的低延时方案。
以下为文章全文:
使用信用卡进行支付的款项是巨大的,但是很明显,通过分析所有的交易,我们也可以从数据中得到内在的价值。比如客户忠诚度、人口统计数据、活动的受欢迎程度、商店的建议和许多其他的统计数据,这对商家和银行来说都是非常有用的,可以改进他们与市场的联系。在Datasalt,我们已经与BBVA银行合作开发了一个系统,该系统能够对多年的数据进行分析,并为网络应用程序和移动应用程序提供不同的方案和统计资料。
我们除了需要对面处理大数据输入这个主要挑战外,还要面对大数据的输出,甚至输出量比输入量还要大。并且需要在高负载下提供更快捷的输出服务。
我们开发的解决方案中有一个每月只需几千美元的基础设施成本,这要感谢使用的云(AWS)、Hadoop和Voldemort。在下面的内容中,我们将解释所提出的架构的主要特点。
数据、目标和首要决定
该系统利用BBVA的信用卡在世界各地的商店交易信息作为输入源的分析。很明显,为了防止隐私问题,数据是匿名的、客观的和分离的,信用卡号码被切割。任何因此而产生的见解总是聚集,所以从中得不出任何个人信息。
我们计算每个店和每个不同的时间段的许多统计资料和数据。以下是其中的一些:
•每家店铺的付款金额的直方图
•客户端的保真度
•客户端人口统计
•商店的建议(在这购买的客户还购买了……)、过滤的位置和商店类别等
该项目的主要目标是通过低延迟的网络和移动应用提供所有这些信息到不同的代理(商店、客户)。因此,一个苛刻的要求是要能够在高负载下能够提供亚秒级延迟的服务。因为这是一个研究项目,还需要在代码和要求需要处理方面有一个高度的灵活性。
由于更新的数据只能每一次并不是一个问题,我们选择了一个面向批处理的架构(Hadoop)。并且我们使用Voldemort作为只读存储服务于Hadoop产生的见解,这是一个既简单又超快的键/值存储。
平台
该系统以Amazon Web Services为基础建立。具体地说,我们用S3来存储原始输入数据,用Elastic MapReduce(亚马逊提供的Hadoop)分析,并用EC2服务于结果。使用云技术使我们能够快速迭代和快速交付功能原型,而这正是我们需要那种项目。
体系架构
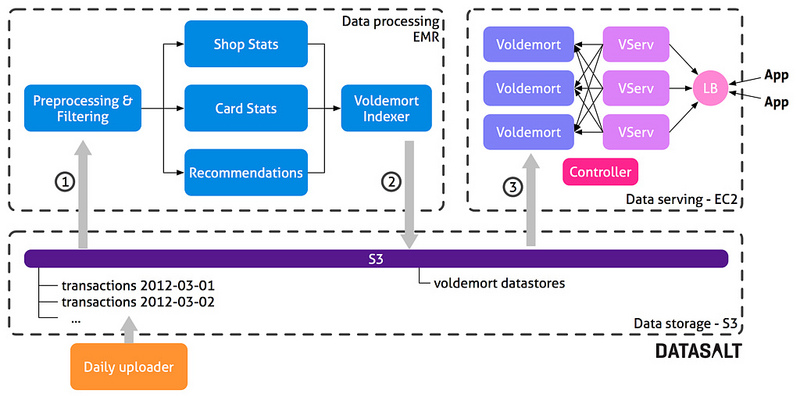
该架构具有三个主要部分:
•数据存储:用户保持原始数据(信用卡交易)和得到的Voldemort商店。
•数据处理:Hadoop的工作流程在EMR上运行,执行所有计算并通过Voldemort创建所需要的数据存储。
•数据服务:一个Voldemort集群从数据处理层提供预先计算好的数据。
每一天,银行上传在那一天发生的所有交易到S3上的一个文件夹中。这可以让我们保留所有的历史数据——每天所有的信用卡执行的交易。所有的这些数据都被输入处理层,所以我们每天都会重新计算一切,之后再处理这些数据,我们就能够非常灵活。如果需求变更或如果我们找到一个愚蠢的错误,我们只需要在下一批中更新项目代码和所有的固定数据就可以了。这让我们作出了一个开发的决定:
•一个简化代码的基础架构
•灵活性和适应性的变化
•易于操作的人为错误(刚刚修复的错误,并重新启动的过程)
每天,控制器都会在EMR上启动一个新的Hadoop集群以及启动处理流程。这个流程由约16组MapReduce工作组成,计算各种方案。最后的一部分流程(Voldemort索引)负责构建稍后会部署到Voldemort的数据存储文件。一旦流程结束,得出的数据存储文件就会上传到S3上。控制器关闭Hadoop集群,并发送一个部署请求给Voldemort。然后,Voldemort会从S3上下载新的数据存储,并执行一个热交换,完全取代旧的数据。
技术
Hadoop和Pangool
整个分析和处理流程使用Pangool Jobs在Hadoop基础上。这给我们带来了良好的平衡性、灵活性和敏捷性。元组的使用使我们在流程之间使用简单的数据类型(int、string)传送信息,我们可以把其他复杂对象(如柱状图)与他们自己的自定义进行序列化。
而且,因为Pangool仍然是一个低级别API,我们可以在需要时细调大量单个作业。
Voldemort
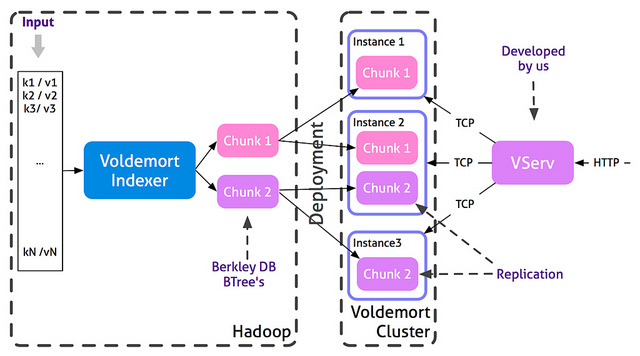
Voldemort是一个分布式键-值(Key-value)存储系统,是亚马逊Dynamo的一个开源克隆。
Voldemort背后的主要想法是在组块中分隔数据。每个组块都被复制,并担任Voldemort集群的节点。每个Voldemort守护进程都能够路由查询节点,以保持一个特定的键值。Voldemort支持快速读取和随机写入,但在这个项目中,我们使用Voldemort作为只读数据存储,在每个批处理过程取代所有数据组块。因为数据存储预先由Hadoop生成、查询服务不受部署过程影响。这是使用这种只读、批处理方法的优点之一。我们也改变集群拓扑结构的相当简易的方法,并可在需要的时候重新平衡数据。
Voldemort提供了一个Hadoop的MapReduce作业,创建数据存储在一个分布式集群。每数据块仅仅是是一个Berkeley DB的B树。
Voldemort的接口是TCP,但我们想使用HTTP服务数据。VServ是一个简单的HTTP服务器,它将传入的HTTP请求转换为Voldemort TCP请求。负载均衡器负责所有VServs之间的共享查询。
计算的数据
统计
部分分析包含计算简单的统计数据:最大值、最小值、平均值、标准偏差、独特的技术等。他们都使用众所周知的MapReduce方法来实现,但我们也计算一些柱状图。为了有效地在Hadoop实现它们,我们创建了一个自定义的柱状图,可以在一次遍历中计算。此外通过各个业务相应的柱状图,我们只需要一步MapReduce,就可以为所有的业务做任何周期的简单统计。
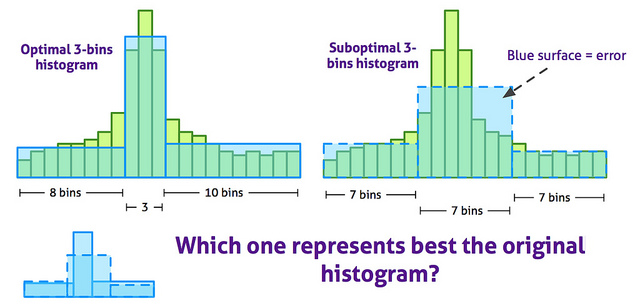
为了减少柱状图所使用的存储量,并改善其可视化,原来的计算柱状图中许多小的项目被转化成几个大的不同宽度的项目。下图显示了一个特定的柱状图转化的最佳方案:
使用随机重启爬山近似算法对最佳柱状图进行计算。下面的图显示了每个爬山迭代上可能的变动:
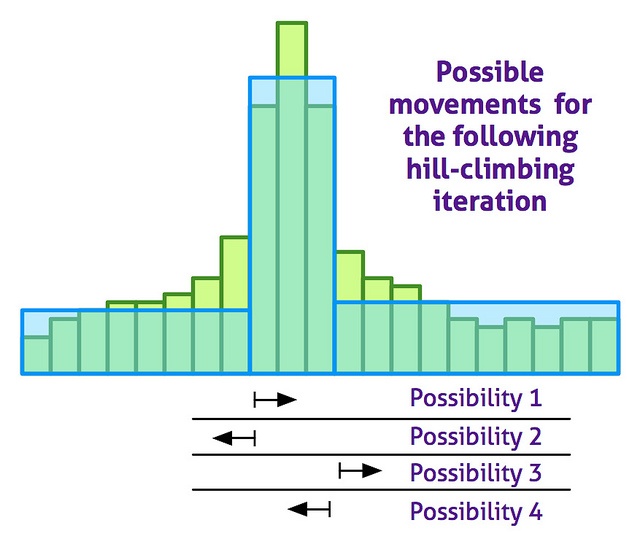
该算法已被证明是非常快速、准确的:相比一个精确的动态算法,我们已经实现了99%的准确率,这是高速增长的因素之一。
商务建议
建议使用同现(co-ocurrences)计算。也就是说,如果有人A和B这两个商店都买了东西,那么A和B之间存在一个同现。只有一个同现考虑,即使客户在A和B购买了好几次。
但同现这一简单想法被使用还需要一些改进。首先,最受欢迎的商店都使用一个简单的频率删减过滤掉,因为几乎每个人都会在他们那购买,所以没有价值再推荐它们。按位置、按商店类别或同时进行过滤推荐,也改善了建议。基于时间的同现会产生较热建议与“总是正确”的建议之间的较量。在可能出现并发行为的地方(用户在购买后看见推荐商品又买了第二件)限制时间。
尽管一些挑战不容易克服,但Hadoop和Pangool仍然是计算同现和生成建议的完美工具。特别是如果一个买家在许多商店进行支付行为,这个信贷调用将显示同现的数量二次增长,使分析不是成线性比例。因为这种情况极少出现,所以我们只限制每张卡的同现的数量,只考虑那些买家在哪买的最多。
成本和一些数字
在Voldemort统计的,在西班牙使用的BBVA信用卡一年的交易信息量270GB。整个处理流程将在一个24“m1.large”集群上运行11个小时。整个基础设施,包括EC2实例所需要的服务所产生的数据将每月花费3500美元。
虽然仍有优化的空间,但考虑到解决方案是敏捷的、灵活的并且在云中,这个价格还是相当合理的。系统运行在一个内部基础设施的成本会便宜很多。
结论与未来
幸好有了像Hadoop、Amazon Web Services和NoSQL数据库这样的技术,才可以以合理的成本,迅速发展可扩展的、灵活的解决方案。
未来的工作将涉及通过Splout SQL替代Voldemort,将允许部署hadoop生成的数据集,扩展了低延迟的键/值到低延迟的SQL。这将减少分析时间并“实时”执行许多聚合的数据量。